Basic AWS Setup for Cloud Computing
Absctract
In this article I am writing down how I used aws ec2 to build my own computing cluster, and run basic streaming process using Kafka, HDFS, Spark, Cassandra.
Machines & Stacks
I used four ec2 m4.large instances, each running Ubuntu 16.04 ami. Each has 2 cores, 8G RAM, and 200G HDD disk. On this 4-node cluster, I deployed:
- Spark cluster in standalone mode, with one node being master and three others being workers.
- Hadoop cluster, with the namenode being the same as the Spark master node, and other three nodes being data nodes.
- Cassandra running on all four nodes.
- Kafka broker and producer is running on the Spark master node, consumer is running in any Spark driver process.
The Hadoop cluster is mostly to provide its hdfs to support submitting Spark jobs in cluster mode, checkpoint for Spark’s stateful streaming process, as well as feeding Kafka producer. The data flow looks like:
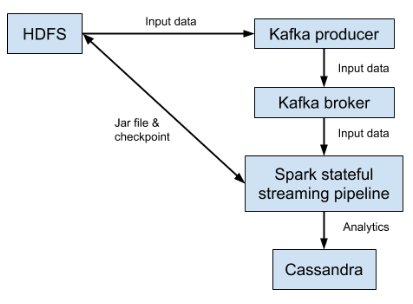
Deploy Spark in standalong mode
- Spin up 4 ec2 instances with Ubuntu 16.04 ami.
- Download pre-built spark on each of them.
- Choose one to be master, the other 3 to be workers. Copy master’s security key onto workers so that master can reach workers through ssh. (which enables the master to spin up the workers through script as in step 5)
- On master node, add 3 workers’ public (TODO can it be private) dns into the $SPARK_HOME/conf/slaves file.
- On master node, run $SMAPRK_HOME/sbin/start-all.sh
- [optional] add
export SPARK_PUBLIC_DNS="blabla"to $SPARK_HOME/conf/spark-env.sh, for master and each worker. This is necessary to make the spark web UI work, otherwise the hyper links in the UI are all using a node’s private dns.
After the Spark cluster is deployed, the 8080 port of the master machine should look like:
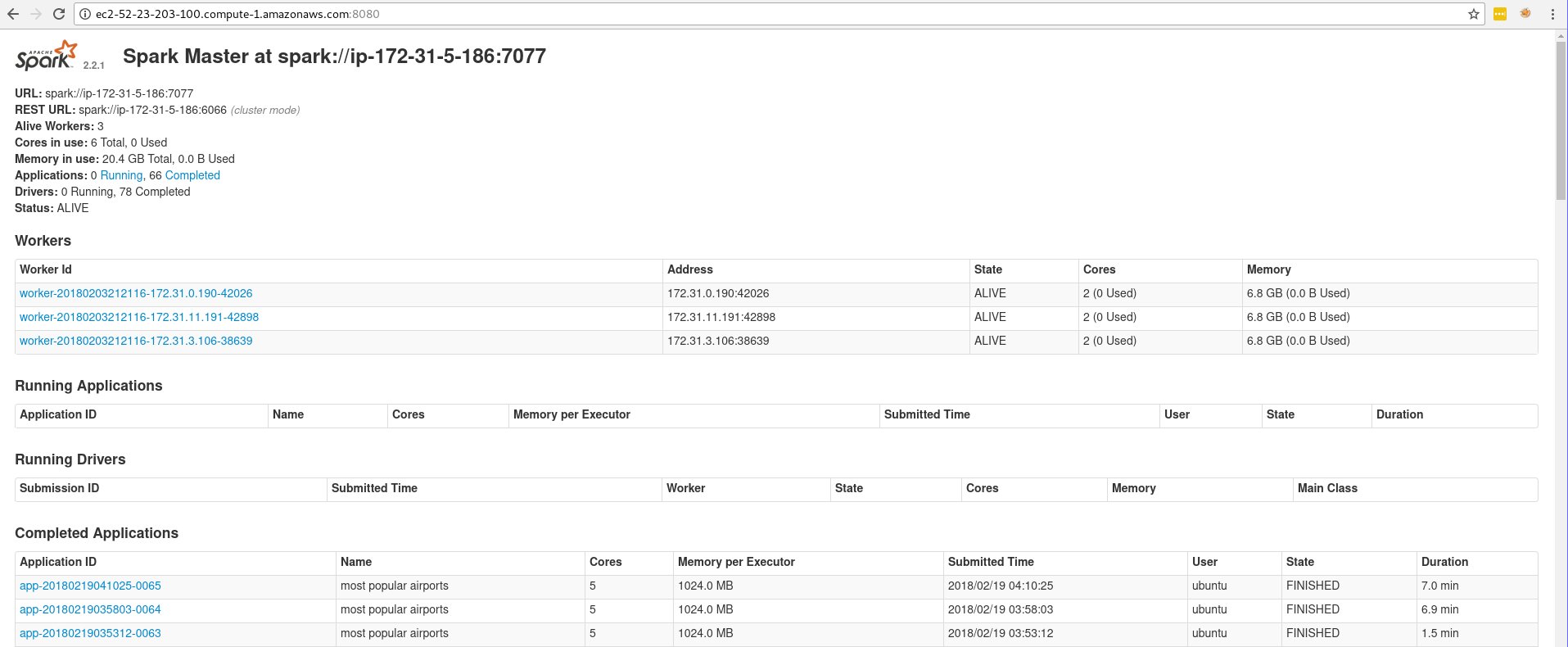
Note that Spark in standalone mode, by itself, is almost useless because there is no hadoop or hdfs that comes along with the Spark in its standalone mode. As a result I can hardly submit any job in cluster mode, because the spark-submit command requires to provide jar file that all nodes can access. Without hdfs, I need to copy the same jar onto every single node and make sure they are in exact same path, plus I have no clue how to let each node output any cloud computing result.
Deploy Hadoop cluster
Simplest way is to follow this post.
Most import lesson I learned, and also a weird feature I found, is that you need a user with name ‘hadoop’ on every node in the cluster. Also note that the ‘hadoop’ user on namenode needs to be able to ssh to slave nodes.
After Hadoop cluster is deployed, the 50070 port of the namenode should look like:
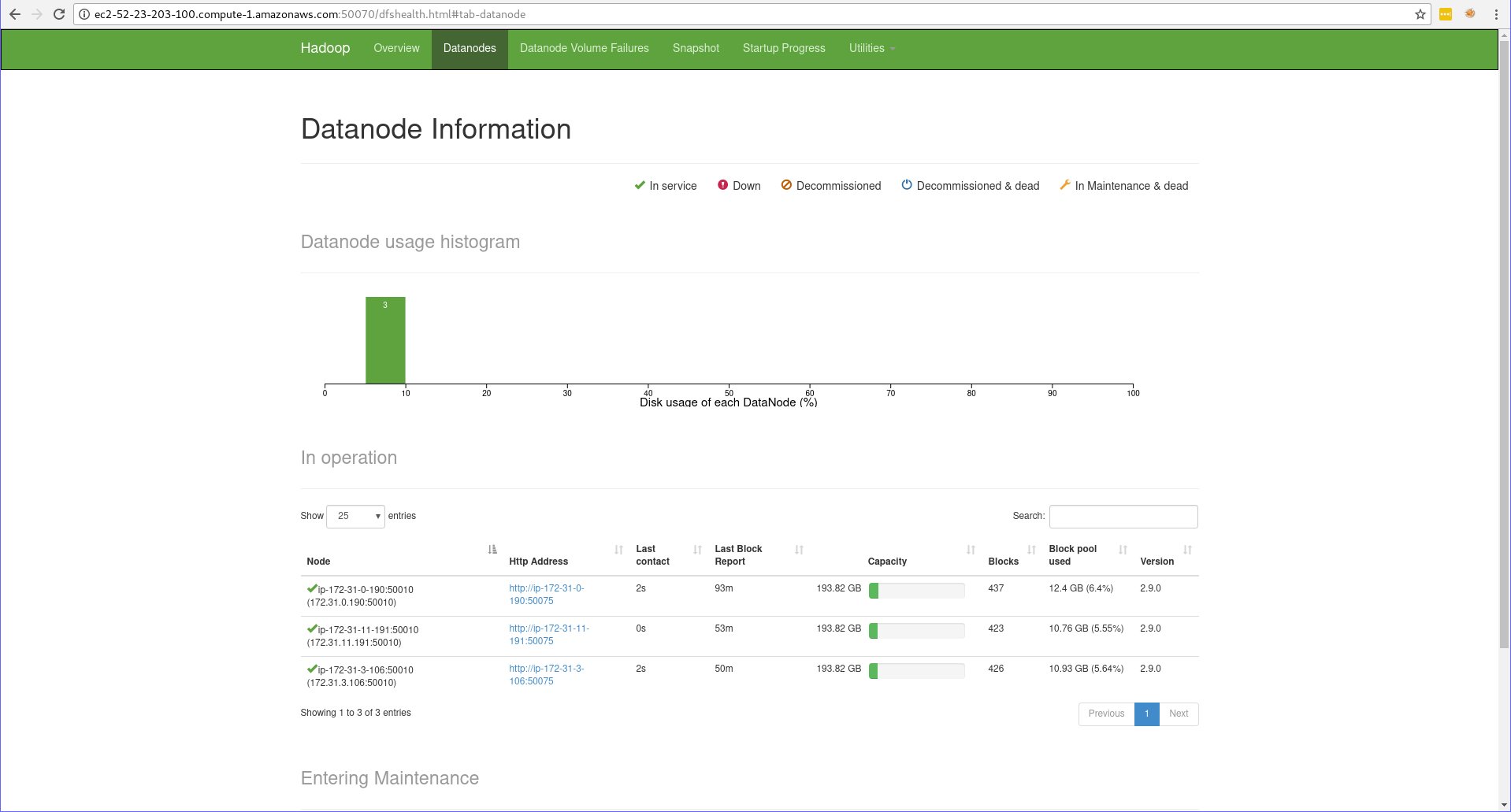
Deploy Cassandra cluster
Use java 8, because java 9 doesn’t work well with cassandra 3.11. Cassandra is easier to deploy since it’s de-centralized and I just need to start cassandra separately on each node, after that the Gossip membership list mechanism will automatically add the node into the cluster.
After the Cassandra cluster is deployed, you can check the status by running nodetool status on any node. Example:
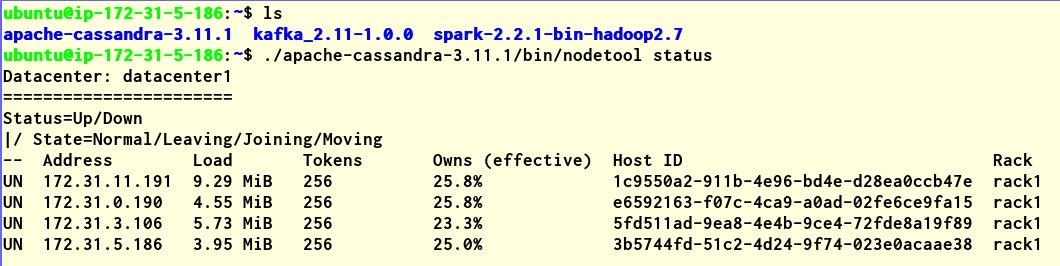
Ingest data through Kafka
Following Kafka’s quick start guide, and that’s pretty much it. You pipe file to the producer, and spin up the consumer on a spark driver node, and the Spark job pumps data through pipeline.
Spark code looks like:
val topicsSet = Set("cleaned_data")
val kafkaParams = Map[String, String]("metadata.broker.list" -> "172.31.5.186:9092")
val messages = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, topicsSet)
// 'messages' is the RDD that your Spark pipeline starts with.